TL;DR
BigDocs is a large-scale multimodal dataset designed to enhance document understanding through 7.5 million diverse samples across 30 tasks. It empowers models to tackle complex document challenges with innovative tasks involving multimodal code generation, reasoning over graphical user interfaces (GUI), websites and documents and generating code from images.
- Bridging the Document AI Gap With comprehensive multimodal samples, enabling models to move beyond basic OCR.
- Complete Transparency With clear documentation and permissive licensing for broad use.
- Real-World Innovation Through novel tasks like GUI reasoning and multimodal code synthesis.
- Performance Gains With up to 15.14% improvement on document benchmarks when training with BigDocs.
What is BigDocs?
BigDocs is a multimodal dataset effort for advanced document understanding, consisting of two key components:
- BigDocs-7.5M: A high-quality, open-access, large-scale dataset of 7.5 million multimodal documents spanning 30 tasks
- BigDocs-Bench: A benchmark suite with 10 real-world-inspired tasks like reasoning over graphical user interfaces (GUI), websites and documents and generating code from images
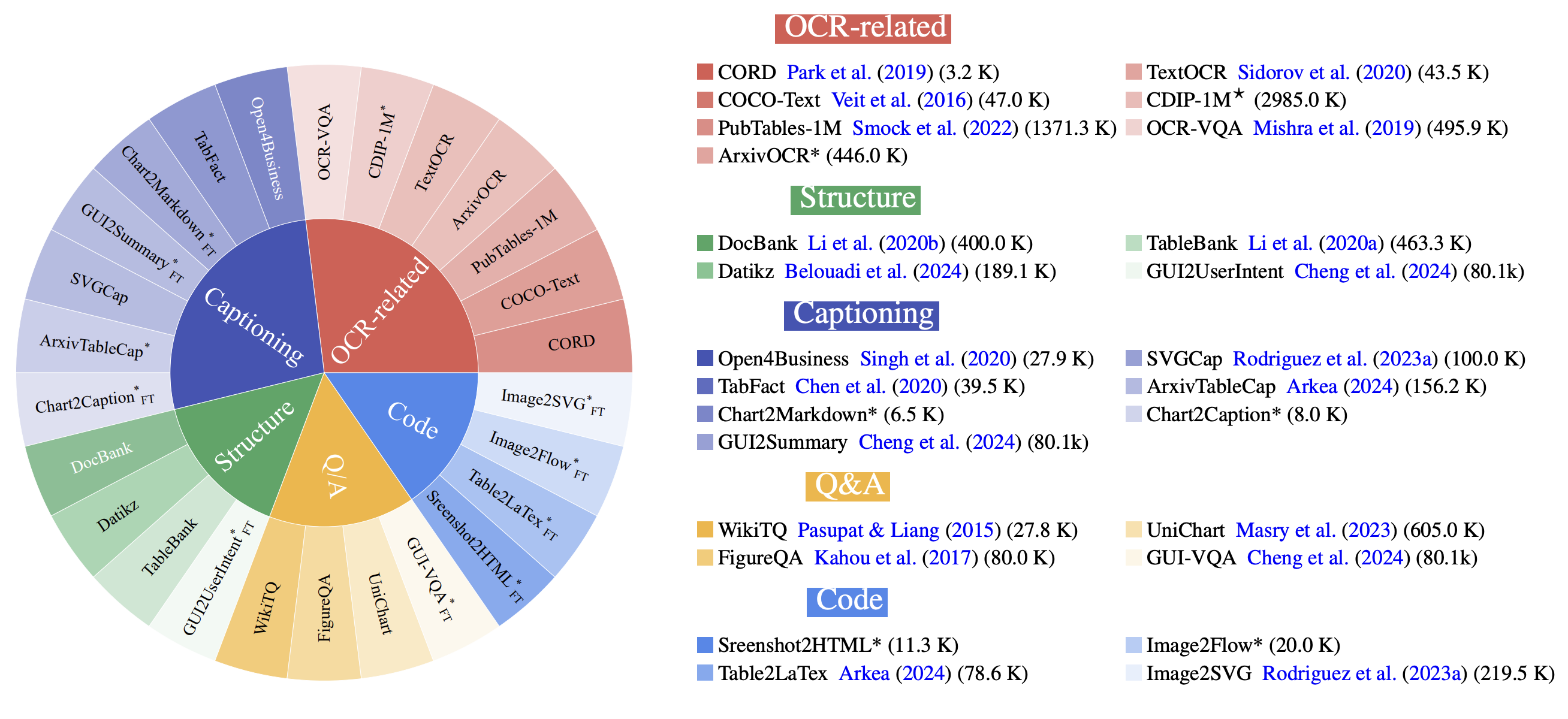
BigDocs-Bench Datasets & Tasks
BigDocs-Bench comprises a diverse set of tasks designed to evaluate model performance across different document understanding scenarios. Below is a detailed breakdown of the dataset composition for each task:
| Task | Train | Val | Test | Hidden | Tokens |
|---|---|---|---|---|---|
|
Screenshot-2HTML
|
9.3K | 1000 | 500 | 500 | 32.7K±53K |
|
Table-2LaTeX
|
77.7K | 1000 | 500 | 500 | 438±540 |
|
Image2SVG
|
198K | 2000 | 748 | 500 | 2.9K±1.7K |
|
Image2Flow (GraphViz)
|
8.0K | 1000 | 500 | 500 | 418±124 |
|
Image2Flow (JSON)
|
8000 | 1000 | 500 | 500 | 1800±601 |
|
Chart-2Markdown
|
4500 | 1000 | 500 | 500 | 1.6K±4.4K |
|
Chart2Caption
|
5.4K | 1300 | 650 | 500 | 94±49 |
|
GUI2UserIntent
|
79K | 1000 | 500 | 500 | 28±4 |
|
GUI2Summary
|
79K | 1000 | 500 | 500 | 132±25 |
|
GUI-VQA
|
78.9k | 1000 | 500 | 500 | 35±24 |
BigDocs-Bench Leaderboard
Our comprehensive evaluation demonstrates the effectiveness of models fine-tuned on BigDocs. The leaderboard below showcases performance comparisons across various metrics, highlighting the improvements achieved through our approach:
| Model | Chart2MD | Chart2Cap. | Image2Flow (GraphViz) | Image2Flow (JSON) | GUI2Sum. | GUI2Intent | Image2SVG | Screenshot2HTML | Table2Latex | GUI-VQA | Avg. Score |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DocOwl-1.5-8B | 0.08 | 18.69 | 0.00 | 0.00 | 11.22 | 13.88 | 3.58 | 3.50 | 75.07 | 27.22 | 15.32 |
| Qwen2-VL-2B | 41.17 | 22.88 | 0.00 | 0.00 | 23.98 | 17.70 | 23.18 | 6.46 | 74.83 | 26.40 | 23.66 |
| Phi3.5-V-4B | 60.64 | 21.88 | 1.61 | 0.65 | 27.80 | 10.81 | 34.57 | 4.25 | 74.14 | 34.96 | 27.13 |
| LLAVA-NeXT-7B | 22.00 | 20.67 | 1.58 | 0.46 | 21.99 | 12.38 | 20.53 | 5.00 | 73.81 | 27.54 | 20.60 |
| Idefics2-8B | 25.34 | 20.95 | 1.17 | 0.00 | 8.75 | 5.06 | 37.73 | 3.56 | 74.50 | 27.76 | 20.48 |
| Llama-3.2.90B | 45.21 | 20.60 | 0.73 | 0.52 | 22.16 | 12.04 | 45.97 | 7.32 | 74.79 | 27.28 | 25.66 |
| Qwen2-VL-72B | 70.47 | 19.42 | 1.07 | 0.23 | 18.80 | 33.94 | 54.43 | 10.03 | 74.51 | 30.67 | 31.36 |
| GeminiPro-1.5 | 66.70 | 25.23 | 22.66 | 27.28 | 27.12 | 17.57 | 60.34 | 10.33 | 74.65 | 36.58 | 36.84 |
| DocOwl-1.5-8B + BigDocs | 54.81 | 23.59 | 13.92 | 37.46 | 26.45 | 13.12 | 25.46 | 9.70 | 74.44 | 26.58 | 30.55 |
| LLAVA-NeXT-7B + BigDocs | 76.63 | 25.90 | 11.51 | 33.59 | 25.54 | 16.79 | 15.21 | 7.43 | 75.22 | 35.35 | 32.32 |
| Idefics2-8B + BigDocs | 74.43 | 33.38 | 42.16 | 48.54 | 45.55 | 89.15 | 33.66 | 3.64 | 81.28 | 43.46 | 49.52 |
| Llama-3.2.90B + BigDocs | 72.25 | 33.74 | 41.61 | 52.11 | 42.59 | 71.65 | 33.51 | 9.20 | 78.54 | 33.97 | 46.92 |
| Qwen2-VL-2B + BigDocs | 72.78 | 32.88 | 59.66 | 71.49 | 46.14 | 79.55 | 60.63 | 10.40 | 80.79 | 40.67 | 55.50 |
| Qwen2-VL-2B (base) + BigDocs (Ours) | 84.01 | 36.78 | 63.07 | 71.86 | 47.32 | 86.91 | 34.65 | 12.05 | 81.94 | 44.81 | 56.34 |
Current Limitations in the Field
Despite recent advances in document AI, several challenges persist in the field. We identify three key limitations that BigDocs aims to address:
Scarcity of Open Datasets
Many datasets for training VLMs are not publicly available, with limited transparency about their content.
Simple Tasks in Open Datasets
Public datasets often address only basic tasks, insufficient for complex real-world challenges.
Restrictive Licensing
Unclear or restrictive licenses make many datasets difficult to use for business purposes.
BigDocs-7.5M Dataset
The BigDocs-7.5M dataset represents a significant advancement in document understanding, offering comprehensive coverage across multiple domains and tasks. Our dataset is structured around three primary categories:
Task Categories
Document Information Extraction
Enhanced OCR, layout analysis, and table detection
Document Understanding
Document classification, question answering, and diagram analysis
Document Creation and Manipulation
Transform visual data into HTML, LaTeX, Markdown and JSON
Results of Training on BigDocs-7.5M
Our experimental results demonstrate significant improvements across multiple benchmarks, showcasing the effectiveness of training with BigDocs-7.5M:
Performance Boost
Up to 34.5% improvement through fine-tuning on BigDocs, enabling superior document understanding capabilities.
Competitive Edge
Surpasses proprietary models by 25.8% on BigDocs-Bench, demonstrating the dataset's excellence for real-world tasks.
| Model | DocVQAVAL | InfoVQAVAL | DeepFormTEST | KLCTEST | WTQTEST | TabFactTEST | ChartQATEST | TextVQAVAL | MMIMTEST | DudeMiniTEST | SlideVQA-MTEST | TableVQATEST | Avg. Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DocOwl1.5-8B (instruct) | 80.73 | 49.94 | 68.84 | 37.99 | 38.87 | 79.67 | 68.56 | 68.91 | 33.67 | 34.64 | 31.62 | 52.60 | 53.84 |
| DocOwl1.5-8B (base) | 2.07 | 1.84 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 24.44 | 19.07 | 3.30 | 13.63 | 5.36 |
| DocOwl1.5-8B (base) + DocStruct4M | 75.99 | 46.88 | 62.77 | 35.21 | 32.86 | 71.56 | 68.36 | 65.08 | 33.67 | 29.00 | 27.03 | 46.27 | 49.56 |
| DocOwl1.5-8B (base) + BigDocs (Ours) | 78.70 | 47.62 | 64.39 | 36.93 | 35.69 | 72.65 | 65.80 | 67.30 | 32.33 | 32.55 | 29.60 | 49.03 | 51.05 |
| Qwen2-VL-2B (instruct) | 89.16 | 64.11 | 32.38 | 25.18 | 38.20 | 57.21 | 73.40 | 79.90 | 42.00 | 45.23 | 46.50 | 43.07 | 53.03 |
| Qwen2-VL-2B (base) | 7.26 | 0.78 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.14 | 34.89 | 28.43 | 14.55 | 0.00 | 7.25 |
| Qwen2-VL-2B (base) + DocStruct4M | 59.53 | 32.00 | 53.98 | 36.38 | 28.48 | 64.24 | 54.44 | 55.89 | 34.89 | 28.78 | 22.68 | 46.53 | 43.15 |
| Qwen2-VL-2B (base) + BigDocs (Ours) | 57.23 | 31.88 | 49.31 | 34.39 | 31.61 | 64.75 | 68.60 | 61.01 | 35.67 | 27.19 | 17.46 | 47.53 | 43.89 |
| Phi3.5-Vision-4B (instruct) | 86.00 | 56.20 | 10.47 | 7.49 | 17.18 | 30.43 | 82.16 | 73.12 | 46.00 | 37.20 | 30.93 | 70.70 | 45.66 |
| Phi3.5-Vision-4B + DocStruct4M | 86.76 | 68.90 | 70.12 | 37.83 | 51.30 | 82.12 | 79.76 | 68.60 | 44.11 | 35.52 | 31.90 | 69.17 | 60.51 |
| Phi3.5-Vision-4B + BigDocs (Ours) | 87.05 | 70.05 | 70.97 | 37.45 | 51.21 | 81.24 | 81.56 | 68.72 | 45.00 | 36.15 | 32.47 | 67.77 | 60.80 |
| LLAVA-NeXT-7B (instruct) | 63.51 | 30.90 | 1.30 | 5.35 | 20.06 | 52.83 | 52.12 | 65.10 | 38.89 | 17.94 | 7.46 | 32.87 | 32.36 |
| LLAVA-NeXT-7B + DocStruct4M | 60.95 | 26.14 | 39.78 | 28.34 | 25.90 | 67.72 | 61.20 | 52.25 | 25.78 | 21.70 | 15.33 | 27.03 | 37.68 |
| LLAVA-NeXT-7B + BigDocs (Ours) | 57.13 | 24.47 | 46.38 | 31.09 | 27.06 | 72.58 | 54.72 | 49.06 | 17.78 | 22.88 | 16.07 | 33.13 | 37.70 |
Citation
If you find this work useful for your research, please consider citing our paper:
@misc{rodriguez2025bigdocsopendatasettraining,
title={BigDocs: An Open Dataset for Training Multimodal Models on Document and Code Tasks},
author={Juan Rodriguez and Xiangru Jian and Siba Smarak Panigrahi and Tianyu Zhang and
Aarash Feizi and Abhay Puri and Akshay Kalkunte and François Savard and
Ahmed Masry and Shravan Nayak and Rabiul Awal and Mahsa Massoud and
Amirhossein Abaskohi and Zichao Li and Suyuchen Wang and Pierre-André Noël and
Mats Leon Richter and Saverio Vadacchino and Shubham Agarwal and Sanket Biswas and
Sara Shanian and Ying Zhang and Noah Bolger and Kurt MacDonald and Simon Fauvel and
Sathwik Tejaswi and Srinivas Sunkara and Joao Monteiro and Krishnamurthy DJ Dvijotham and
Torsten Scholak and Nicolas Chapados and Sepideh Kharagani and Sean Hughes and
M. Özsu and Siva Reddy and Marco Pedersoli and Yoshua Bengio and Christopher Pal and
Issam Laradji and Spandana Gella and Perouz Taslakian and David Vazquez and Sai Rajeswar},
year={2025},
eprint={2412.04626},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2412.04626}
}